https://www.youtube.com/watch?v=nOxKexn3iBo
In this comprehensive video tutorial, Jeremy Howard from answer.ai demystifies the process of programming NVIDIA GPUs using CUDA, and simplifies the perceived complexities of CUDA programming. Jeremy emphasizes the accessibility of CUDA, especially when combined with PyTorch's capabilities, allowing for programming directly in notebooks rather than traditional compilers and terminals. To make CUDA more approachable to Python programmers, Jeremy shows step by step how to start with Python implementations, and then convert them largely automatically to CUDA. This approach, he argues, simplifies debugging and development.
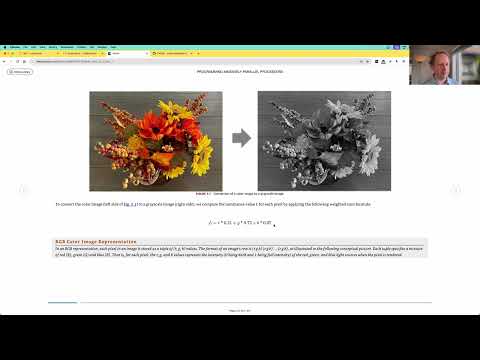
The tutorial is structured in a hands-on manner, encouraging viewers to follow along in a Colab notebook. Jeremy uses practical examples, starting with converting an RGB image to grayscale using CUDA, demonstrating the process step-by-step. He further explains the memory layout in GPUs, emphasizing the differences from CPU memory structures, and introduces key CUDA concepts like streaming multi-processors and CUDA cores.
Jeremy then delves into more advanced topics, such as matrix multiplication, a critical operation in deep learning. He demonstrates how to implement matrix multiplication in Python first and then translates it to CUDA, highlighting the significant performance gains achievable with GPU programming. The tutorial also covers CUDA's intricacies, such as shared memory, thread blocks, and optimizing CUDA kernels.
The tutorial also includes a section on setting up the CUDA environment on various systems using Conda, making it accessible for a wide range of users.
This is lecture 3 of the "CUDA Mode" series (but you don't need to watch the others first). The notebook is available in the lecture3 folder here: https://github.com/cuda-mode/lecture2...