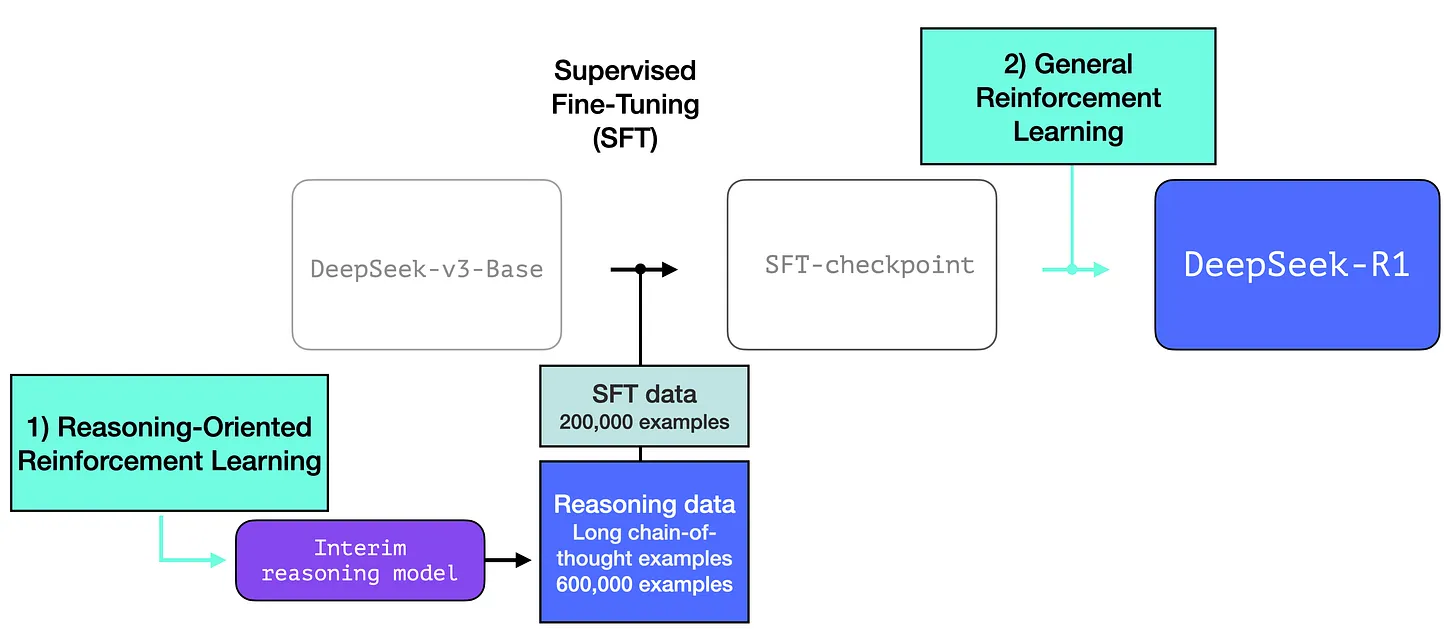
Just like most existing LLMs, DeepSeek-R1 generates one token at a time, except it excels at solving math and reasoning problems because it is able to spend more time processing a problem through the process of generating thinking tokens that explain its chain of thought.